
Ruimao Zhang
Tenure-track Associate Professor ( Computer Vision, Multimedia, Embodied AI )
Spatial Artificial Intelligence Lab, SAILSchool of Electronics and Communication Engineering , Sun Yat-sen University (Shenzhen Campus)
Google Scholar , Twitter , Zhihu
News
The primary objective of our research team is to develop intelligent agents that can effectively collaborate with humans in dynamic environments. To realize this ambition, we focus on three core research directions. (1) Human-centered Visual Content Understanding and Reasoning: This area seeks to enable machines to actively perceive, analyze, and interpret human states, behaviors, and underlying motivations in dynamic scenarios. (2) Omni-modal Scene Perception and Navigation: This emphasizes harnessing diverse sensor modalities to comprehend and navigate complex scenes. (3) Machine Behavior Planning and Decision-making: This direction is centered on equipping intelligent agents with the ability to make real-time decisions based on their comprehension of understanding surroundings.
BIOGRAPHY
“The weak and ignorance is not a barrier to survive, arrogance is"
---《The Three-Body Problem》 Cixin Liu
“No human nature, people will lose a lot; no bestiality, people will not survive“
Ruimao's Publication---《The Three-Body Problem》 Cixin Liu
Education
Postdoctoral Fellow in Multimedia Lab, worked with Prof. Xiaogang Wang ( co-founder of SenseTime ) and Prof. Ping Luo.
Ph.D. in Computer Science and Technology, advised by Prof. Liang Lin ( IEEE/IAPR Fellow, Distinguish Young Scholar of NSFC ).
B.E. in Software Engineering.
Experience
Associate Professor, School of Electronics and Communication Engineering.
Associate Researcher, School of Data Science.
Senior Researcher, report to Prof. Jinwei Gu in SenseBrain, USA.
Visiting Ph.D. Student, advised by Prof. Lei Zhang and Prof. Wangmeng Zuo.
Research Assistant, advised by Prof. Liang Lin.
Awards and Honours
Academic Activity
Associate Editor, ACM Transactions on Multimedia Computing, Communications and Applications (2024.01~present)
Area Chair, International Conference on Learning Representations (ICLR), 2026
Senior Program Committee (SPC) member, European Conference on Artificial Intelligence (ECAI), 2025
Session Chair, International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Part III, 2022
Poster Chair, China Spatial Intelligence Conference (ChinaSI), China, 2025
Executive Area Chair, Vision And Learning SEminar (VALSE), China (2021.07~present)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) --- 2019, 2020, 2021, 2022, 2023, 2024
IEEE International Conference on Computer Vision (ICCV) --- 2019, 2021, 2023, 2025
European Conference on Computer Vision (ECCV) --- 2022, 2024
Neural Information Processing Systems (NeurIPS) --- 2020, 2021, 2022, 2023, 2024
International Conference on Learning Representations (ICLR) --- 2021, 2022, 2024, 2025
International Conference on Machine Learning (ICML) --- 2022, 2023
The Conference on Robot Learning (CoRL) --- 2025
The IEEE/CVF Winter Conference on Applications of Computer Vision --- 2026
International Conference on Artificial Intelligence and Statistics (AISTATS) --- 2025
AAAI Conference on Artificial Intelligence (AAAI) --- 2021
International Conference on Multimedia and Expo (ICME) --- 2014, 2016
IEEE Trans. on Pattern Analysis and Machine Intelligence (T-PAMI)
International Journal of Computer Vision (IJCV)
Artificial Intelligence
ACM Computing Surveys
IEEE Trans. on Neural Network and Learning System (T-NNLS)
IEEE Trans. on Image Processing (T-IP)
IEEE Trans. on Cybernetics (T-CYB)
IEEE Trans. on Circuits and Systems for Video Technology (T-CSVT)
IEEE Trans. on Multimedia (T-MM)
IEEE Trans. on Dependable and Secure Computing (T-DSC)
IEEE Trans. on Information Forensics and Security (T-IFS)
ACM Transactions on Multimedia Computing, Communications and Applications (ACM TOMM)
IEEE Robotics and Automation Letters (RA-L)
Expert Systems with Applications
Pattern Recognition
Neurocomputing
Medical Image Analysis (MIA)
Applied Soft Computing
International Journal of Human-Computer Interaction
"Vision and Learning in Embodied Intelligence" workshop at VALSE, 2024, Chongqing, China
"Autonomous Driving Based on Large-scale Models" workshop at VALSE, 2023, Wuxi, China
"Abdominal Multi-Organ Segmentation Challenge" challenge at MICCAI, 2022, Singapore
"Deep Learning for Medical Big Data Analysis" workshop at VALSE, 2022, Tianjin, China
"Deep Model Architecture" workshop at VALSE, 2021, Hangzhou, China
"Computer Vision for Fashion, Art, and Design" workshop at CVPR, 2020, Virtual
"Computer Vision for Fashion, Art, and Design" workshop at ICCV 2019, Seoul, Korea
PUBLICATION
Preprint
(* indicates corresponding author)
Newly Accepted Articles
(* indicates corresponding author)
- Ziye Wang, Li Kang, Yiran Qin, Jiahua Ma, Zhanglin Peng, Lei Bai, Ruimao Zhang*,
"Reinventing Multi-Agent Collaboration through Gaussian-Image Synergy in Diffusion Policies",
Proc. of Conference on Neural Information Processing Systems ( NeurIPS ), 2025
( We present a novel Gaussian-image synergistic representation that facilitates scalable, perception-aware imitation learning in multi-agent embodied collaborative systems. )
【PDF】
- Jiahua Ma^, Yiran Qin^, Yixiong Li, Xuanqi Liao, Yulan Guo, Ruimao Zhang*,
"CDP:Towards Robust Autoregressive Visuomotor Policy Learning via Causal Diffusion",
Proc. of Conference on Robot Learning ( CoRL ), 2025
( CDP enhances action prediction by conditioning on historical action sequences, thereby enabling more coherent and contextaware visuomotor policy learning. )
【PDF】
- Lai Wei^, Jiahua Ma^, Yibo Hu, Ruimao Zhang*,
"Ensuring Force Safety in Vision-Guided Robotic Manipulation via Implicit Tactile Calibration",
Proc. of Conference on Robot Learning ( CoRL ), 2025
( We introduce a novel state diffusion termed SafeDiff to generate a prospective state sequence from the visual context observation while incorporating real-time tactile feedback to refine the sequence.)
【PDF】
- Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin*, Xiaohong Liu, Xihui Liu, Ruimao Zhang*, Lei Bai*,
"RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints",
Proc. of International Conference on Computer Vision( ICCV ), 2025
( We propose the concept of compositional constraints for embodied multi-agent systems, addressing the challenges arising from collaboration among embodied agents.)
【PDF】
- Enshen Zhou, Yiran Qin, Zhenfei Yin, Zhelun Shi, Yuzhou Huang, Ruimao Zhang*, Lu Sheng*, Jing Shao, "Chain-of-Imagination for Reliable Instruction Following in Decision Making“, Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems ( IROS ), 2025 ( We employ a Chain-of-Imagination (CoI) mechanism to envision the step-by-step process of executing instructions and translating imaginations into more precise visual prompts tailored to the current state. ) 【PDF】
- Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao*, Lei Bai*, Wanli Ouyang, Ruimao Zhang*,
"WorldSimBench: Towards Video Generation Models as World Simulators",
Proc. of International Conference on Machine Learning( ICML ), 2025
( We take the initial step in evaluating Predictive Generative Models up to the S3 stage by introducing both Explicit Perceptual Evaluation and Implicit Manipulative Evaluation)
【PDF】
- Jie Yang, Ailing Zeng, Tianhe Ren, Shilong Liu, Feng Li, Ruimao Zhang*, Lei Zhang, "ED-Pose++: Enhanced Explicit Box Detection for Conventional and Interactive Multi-Object Keypoint Detection“, IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2025 ( The extension version of our CVPR and ICCV papers. ED-Pose for Multi-Object Keypoint Detection.) 【PDF】
- Shunlin Lu, Jingbo Wang*, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai*, Ruimao Zhang*, "ScaMo: Exploring the Scaling Law in Autoregressive Motion Generation Model“, Proc. of IEEE International Conference on Computer Vision and Pattern Recognition( CVPR ), 2025 ( We introduce a scalable motion generation framework and observe the scaling behavior in autoregressive motion generation model for the first time. ) 【PDF】【Code】
- Yiran Qin, Ao Sun, Hong Yuze, Benyou Wang, Ruimao Zhang*, "NavigateDiff: Visual Predictors are Zero-Shot Navigation Assistants“, Proc. of IEEE International Conference on Robotics and Automation( ICRA ), 2025 ( A large vision-language model with a diffusion network, named NavigateDiff, continuously predicts the agent’s potential observations to assist robots in generating robust actions.) 【PDF】
- Chaoqun Wang, Jie Yang, Xiaobin Hong, Ruimao Zhang*, "Unlock the Power of Unlabeled Data in Language Driving Model“, Proc. of IEEE International Conference on Robotics and Automation( ICRA ), 2025 ( This work aims to overcome the barrier of large models' extreme dependence on costly large-scale high-quality annotated data in self-driving scenarios.) 【PDF】
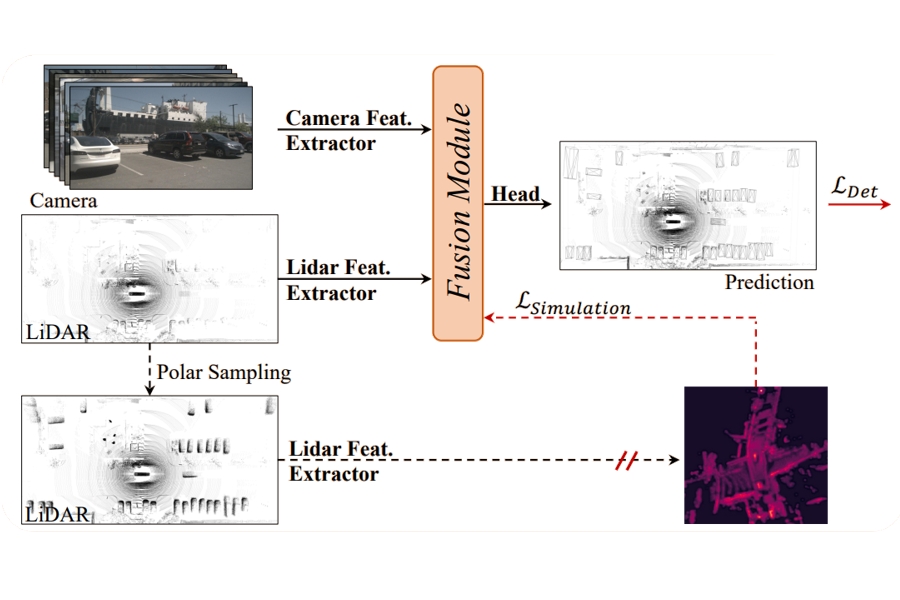
- Chaoqun Wang, Xiaobin Hong, Ruimao Zhang*, "Semantic-Supervised Spatial-Temporal Fusion for LiDAR-based 3D Object Detection“, Proc. of IEEE International Conference on Robotics and Automation( ICRA ), 2025 ( A novel fusion module to address spatial misalignment caused by object motion over time.) 【PDF】
- Ziye Wang, Yiran Qin, Lin Zeng, Ruimao Zhang*, "High-Dynamic Radar Sequence Prediction for Weather Nowcasting Using Spatiotemporal Coherent Gaussian Representation“, Proc. of International Conference on Learning Representations( ICLR ), 2025 (Oral) ( A newly proposed Spatio-Temporal Coherent Gaussian Representation (STC-GS) for dynamic scene prediction, offering a promising way for advancing 4D world model! ) 【PDF】【Project Page】
- Chaoqun Wang, Yiran Qin, Zijian Kang, Ningning Ma, Yukai Shi, Zhen Li, Ruimao Zhang*, "Boosting 3D Object Detection via Self-distilling Introspective Data“, IEEE Transactions on Intelligent Transportation Systems ( T-ITS ), 2025 ( A novel self-distilling paradigm termed SID to boost the accuracy of 3D object detection in both LiDAR-based and LiDAR-Camera-based scenarios.) 【PDF】
Recent Selected Publications ( See Full List )
(* indicates corresponding author)

Principles and Practice of Embodied Intelligence (Chinese Version)
Liang Lin, Ruimao Zhang, Hefeng Wu
ISBN 9787121502668,Publishing House of Electronics Industry (PHEI)
( Systematically outline mainstream technical approaches of embodied intelligence and provide a comprehensive knowledge framework. Comprehensive guide to the key embodied AI technologies, including perception, navigation, manipulation, planning, and collaboration.)
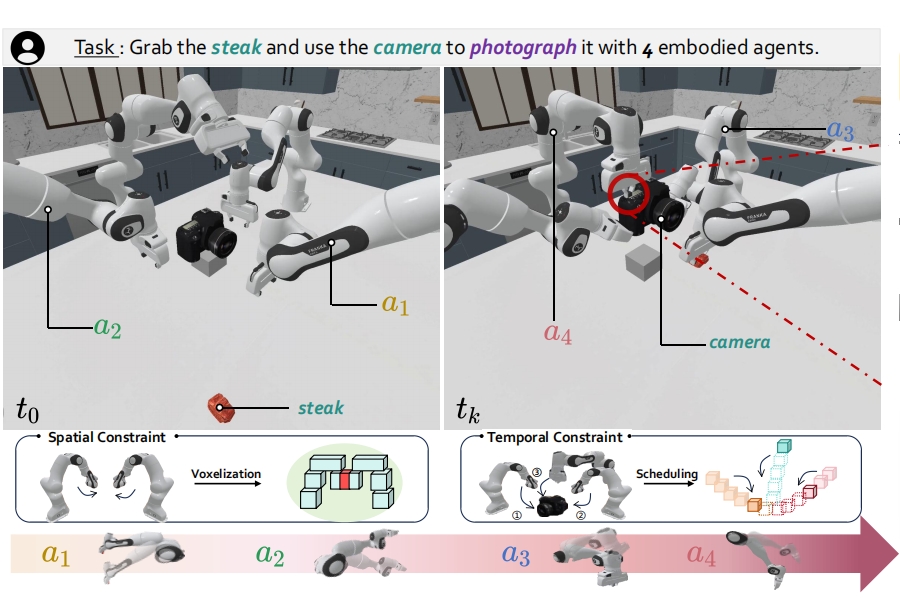
RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin*, Xiaohong Liu, Xihui Liu, Ruimao Zhang*, Lei Bai*
Proc. of International Conference on Computer Vision( ICCV ), 2025 【PDF】
Outstanding Paper Award of CVPR2025 Multi-agent Embodied Intelligence Workshop
( We propose the concept of compositional constraints for embodied multi-agent systems, addressing the challenges arising from collaboration among embodied agents.)
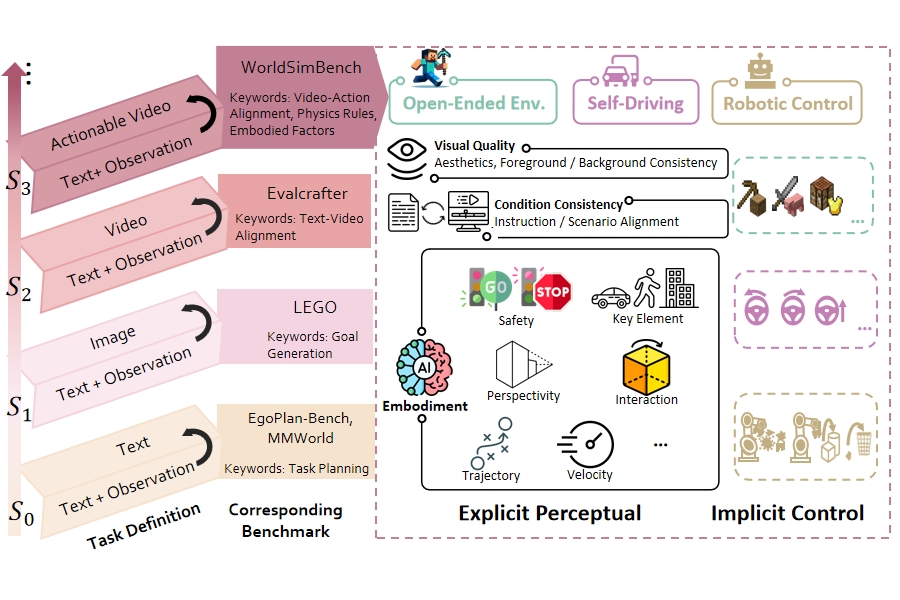
WorldSimBench: Towards Video Generation Models as World Simulators
Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao*, Lei Bai*, Wanli Ouyang, Ruimao Zhang*
Proc. of International Conference on Machine Learning( ICML ), 2025 【PDF】
( We take the initial step in evaluating Predictive Generative Models up to the S3 stage by introducing both Explicit Perceptual Evaluation and Implicit Manipulative Evaluation.)
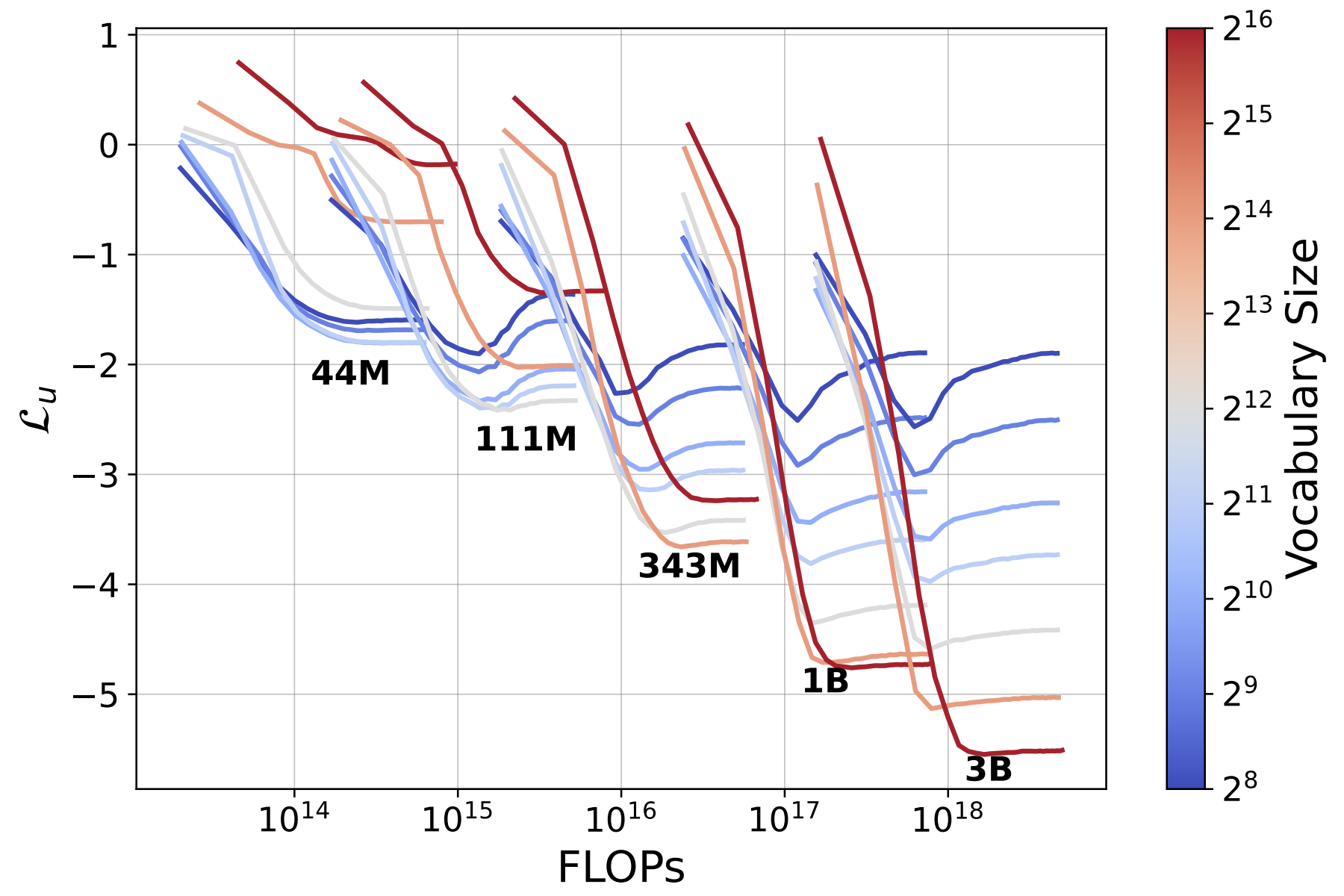
ScaMo: Exploring the Scaling Law in Autoregressive Motion Generation Model
Shunlin Lu, Jingbo Wang*, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai*, Ruimao Zhang*
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition( CVPR ), 2025 【PDF】【Code】
( Scaling behavior in autoregressive motion generation model for the first time. )

High-Dynamic Radar Sequence Prediction for Weather Nowcasting Using Spatiotemporal Coherent Gaussian Representation
Ziye Wang, Yiran Qin, Lin Zeng, Ruimao Zhang*
Proc. of International Conference on Learning Representations( ICLR ), 2025 (Oral) 【Project】
( A newly proposed Spatio-Temporal Coherent Gaussian Representation (STC-GS) for dynamic scene prediction, offering a promising way for advancing 4D world model! )

HumanTOMATO: Text-aligned Whole-body Motion Generation
Shunlin Lu, Ling-Hao Chen, Ailing Zeng, Jing Lin, Ruimao Zhang* , Lei Zhang, Heung-Yeung Shum*
Proc. of International Conference on Machine Learning ( ICML ), 2024【PDF】【Code】
( A novel text-aligned whole-body motion generation framework that can generate high-quality, diverse, and coherent whole body motions. )
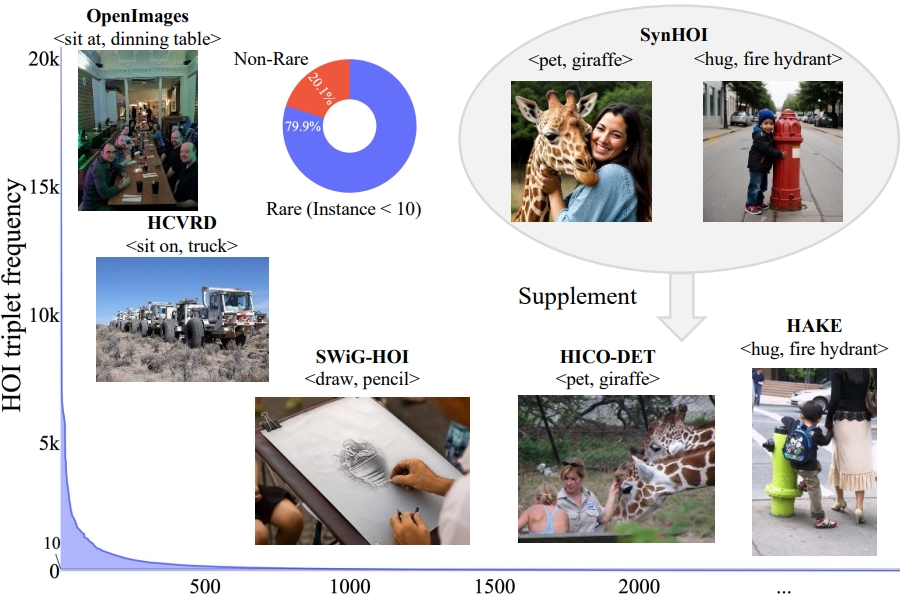
Open-World Human-Object Interaction Detection via Multi-modal Prompts
Jie Yang, Bingliang Li, Ailing Zeng, Lei Zhang, Ruimao Zhang*
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition ( CVPR ), 2024 【PDF】
【Project】
( A novel prompt-based HOI detector designed to leverage both textual descriptions for open-set generalization and visual exemplars for handling high ambiguity in descriptions. )
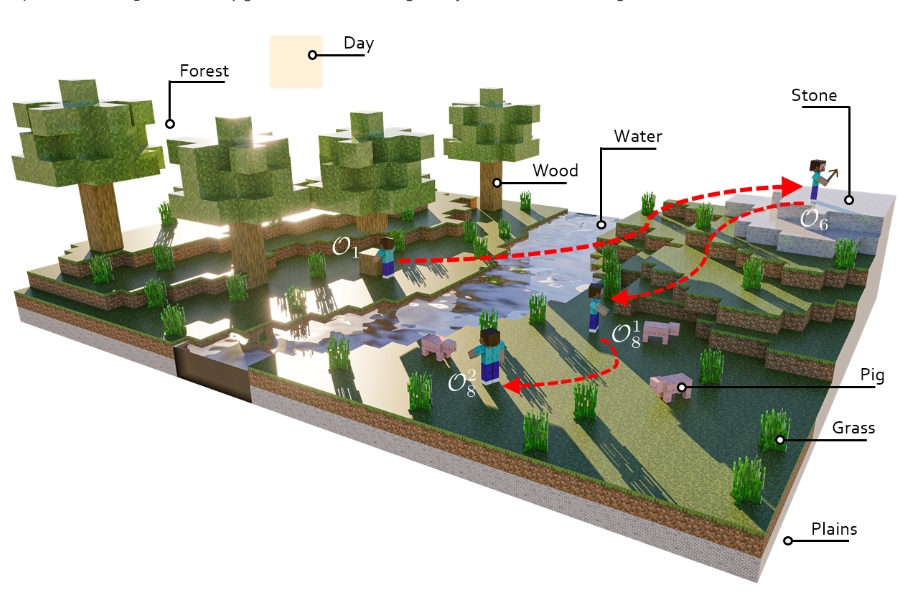
MP5: A Multi-modal Open-ended Embodied System in Minecraft via Active Perception
Yiran Qin, Enshen Zhou, Qichang Liu, Zhenfei Yin, Lu Sheng*, Ruimao Zhang*, Yu Qiao, Jing Shao
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition ( CVPR ), 2024 【PDF】 【Project】
【Youtube】【Bilibili】
( MP5 is an open-ended multimodal embodied system that can conduct situation-aware plans and perform embodied action control via active perception scheme. )

FreeMan: Towards Benchmarking 3D Human Pose Estimation under Real-World Conditions
Jiong Wang, Fengyu Yang, Wenbo Gou, Bingliang Li, Danqi Yan, Ailing Zeng, Yijun Gao, Junle Wang, Ruimao Zhang*
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition ( CVPR ), 2024 【PDF】【Project】
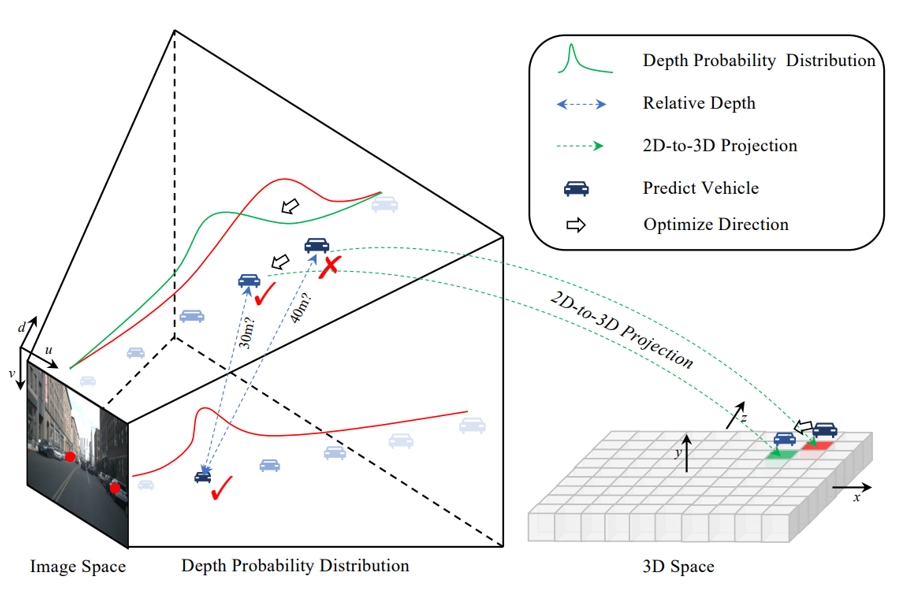
Toward Accurate Camera-based 3D Object Detection via Cascade Depth Estimation and Calibration
Chaoqun Wang, Yiran Qin, Zijian Kang, Ningning Ma, Ruimao Zhang*
Proc. of IEEE International Conference on Robotics and Automation ( ICRA ), 2024
【PDF】
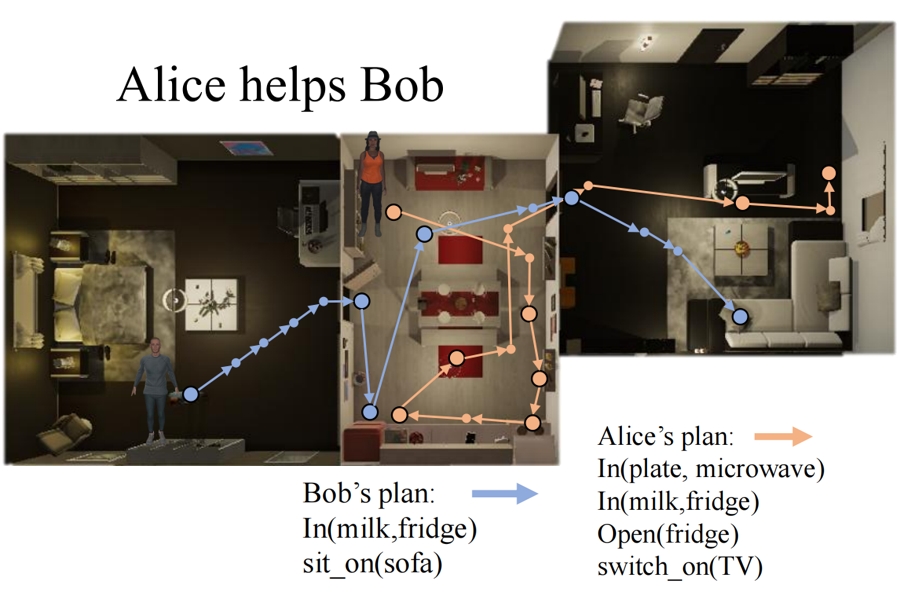
Enhancing Human-AI Collaboration Through Logic-Guided Reasoning
Chengzhi Cao, Yinghao Fu, Sheng Xu, Ruimao Zhang, Shuang Li,
Proc. of International Conference on Learning Representations ( ICLR ), 2024
【PDF】
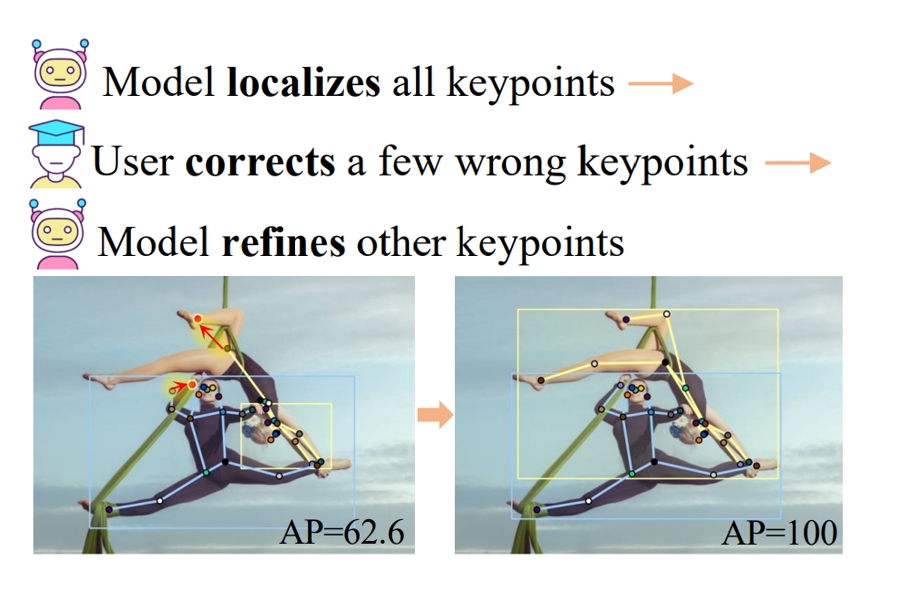
Neural Interactive Keypoint Detection
Jie Yang, Ailing Zeng*, Feng Li, Shilong Liu, Ruimao Zhang*, Lei Zhang
Proc. of IEEE International Conference on Computer Vision ( ICCV ), 2023
【PDF】
【Code】
SupFusion: Supervised LiDAR-Camera Fusion for 3D Object Detection
Yiran Qin, Chaoqun Wang, Zijian Kang, Ningning Ma, Zhen Li, Ruimao Zhang*
Proc. of IEEE International Conference on Computer Vision ( ICCV ), 2023
【PDF】
【Code】
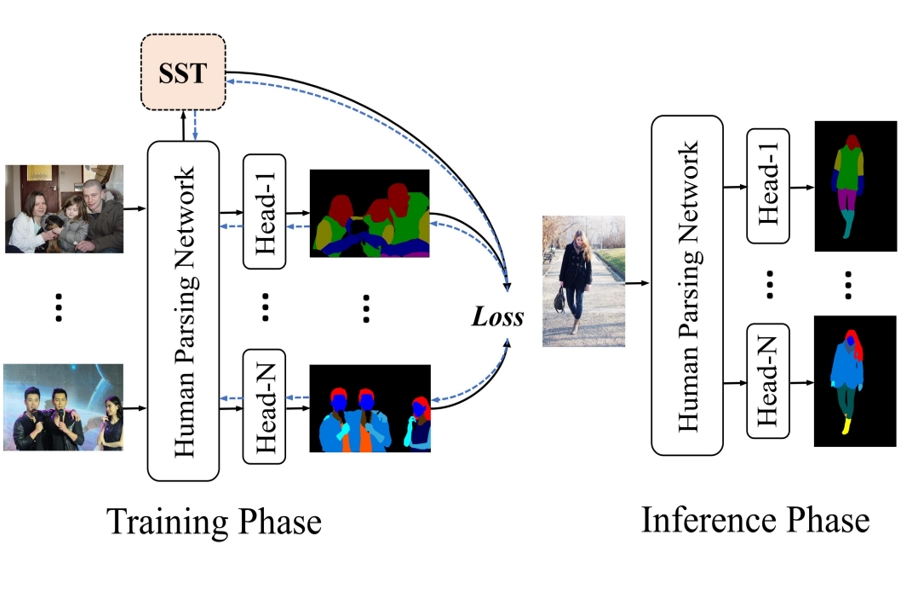
Semantic Human Parsing via Scalable Semantic Transfer over Multiple Label Domains
Jie Yang, Chaoqun Wang, Zhen Li, Junle Wang, Ruimao Zhang*
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition ( CVPR ), 2023
【PDF】【Code】

Inherent Consistent Learning for Accurate Semi-supervised Medical Image Segmentation
Ye Zhu, Jie Yang, Siqi Liu, Ruimao Zhang*
Proc. of Conference on Medical Imaging with Deep Learning( MIDL ), 2023 ( Oral )
【PDF】【Code】
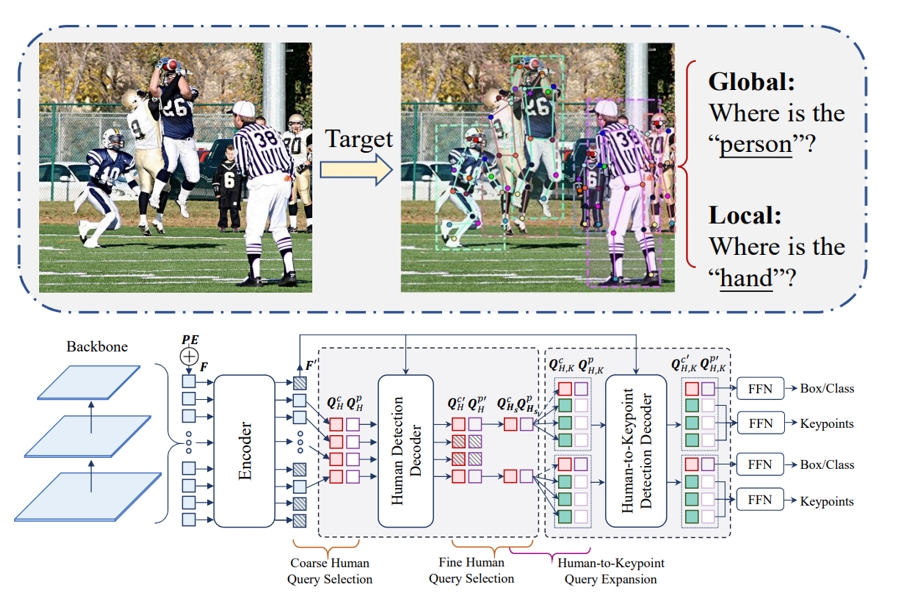
Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation
Jie Yang, Ailing Zeng*, Shilong Liu, Feng Li, Ruimao Zhang*, Lei Zhang
Proc. of International Conference on Learning Representations( ICLR ), 2023
【PDF】【Code】

AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Yuanfeng Ji, Haotian Bai, Jie Yang, Chongjian Ge, Ye Zhu, Ruimao Zhang*, et al.
Proc. of Conference on Neural Information Processing Systems ( NeurIPS ), 2022 ( Oral )
【PDF】【AMOS Challenge】
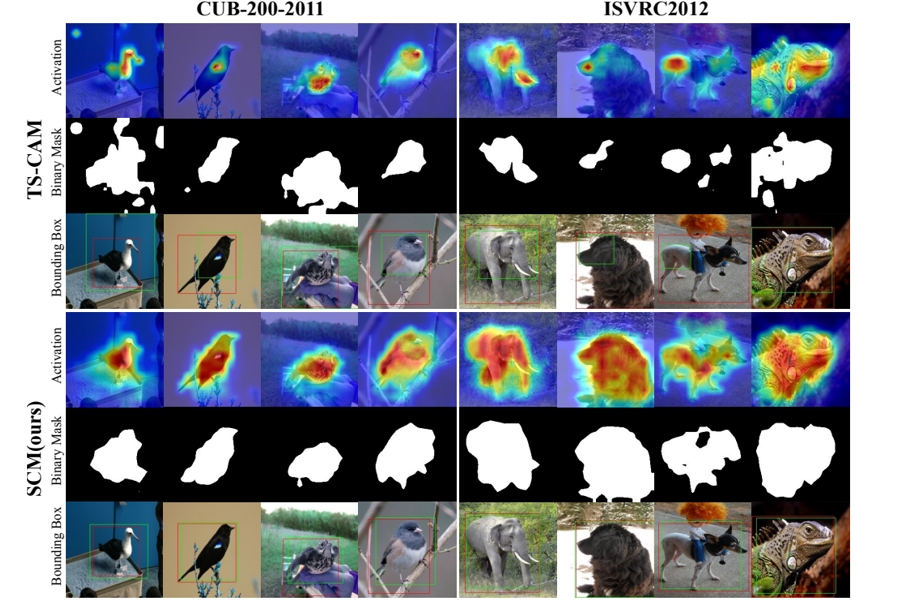
Weakly Supervised Object Localization via Transformer with Implicit Spatial Calibration
Haotian Bai, Ruimao Zhang*, Jiong Wang, Xiang Wan
Proc. of Europe Conference on Computer Vision( ECCV ), 2022
【PDF】
【Code】
【Youtube】
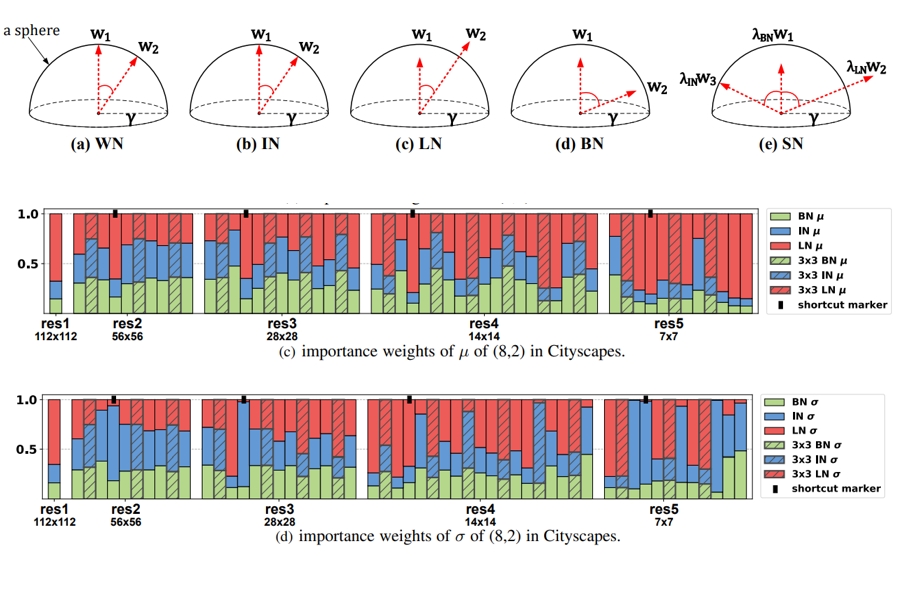
Switchable Normalization for Learning-to-Normalize Deep Representation
Ping Luo, Ruimao Zhang*, Jiamin Ren, Zhanglin Peng, Jingyu Li
IEEE Transactions on Pattern Analysis and Machine Intelligence ( T-PAMI ), 43(2):712-728, 2021
【PDF】
【Code】
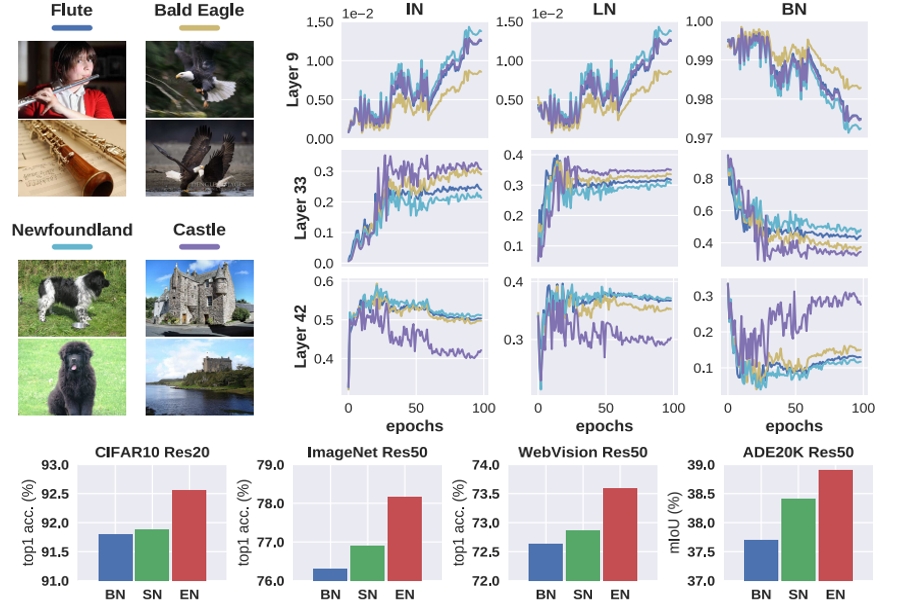
Exemplar Normalization for Learning Deep Representation
Ruimao Zhang, Zhanglin Peng, Lingyun Wu, Zhen Li, Ping Luo
Proc. of IEEE International Conference on Computer Vision and Pattern Recognition ( CVPR ), 2020
【PDF】
【Supp】
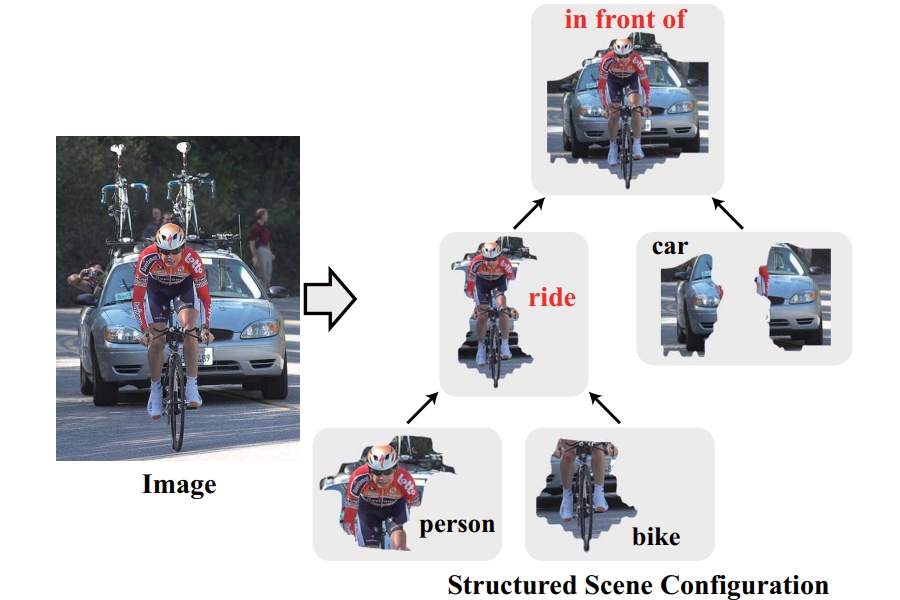
Hierarchical Scene Parsing by Weakly Supervised Learning with Image Descriptions
Ruimao Zhang, Liang Lin, Guangrun Wang, Meng Wang, Wangmeng Zuo
IEEE Transactions on Pattern Analysis and Machine Intelligence ( T-PAMI ), 41(3):596 - 610, 2019
【PDF】
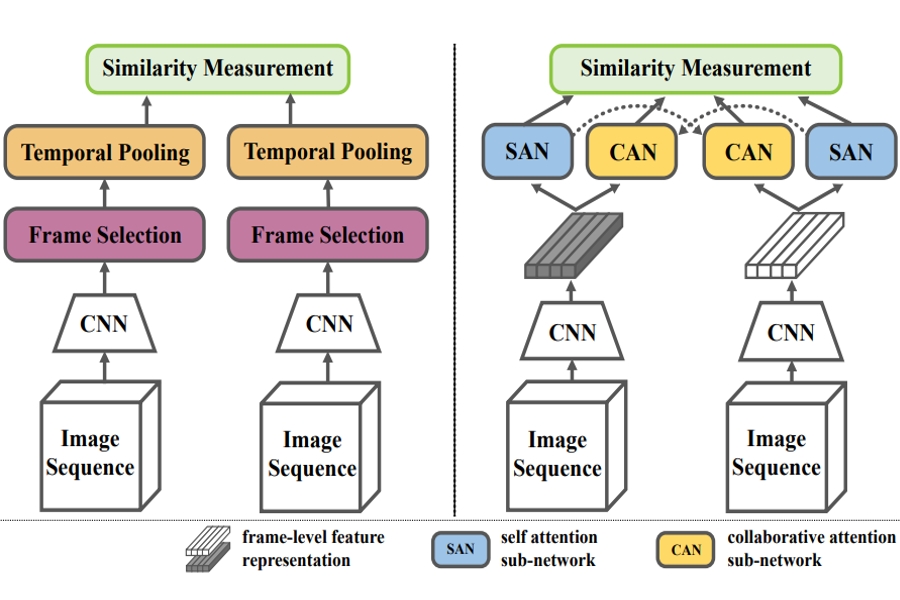
SCAN: Self-and-Collaborative Attention Network for Video Person Re-identification
Ruimao Zhang, Jingyu Li, Hongbin Sun, Yuying Ge, Ping Luo, Xiaogang Wang, Liang Lin
IEEE Transactions on Image Processing ( T-IP ), 28(10):4870-4882, 2019
【PDF】【Code】
MEMBER
Ph.D. Students

Yiran Qin
Ph.D., since 2021, CUHK-SZ
Scene Understanding, Embodied AI, Large Visual Language Model
M.S.: not applicable
B.E.: Shandong University (Top 10%)

Shunlin Lu
Ph.D., since 2023, CUHK-SZ
Human Centric Understanding and Generation, Multi-modal Learning
M.S.: University of Southern California
B.E.: Wuhan University of Technology

Jiahua Ma
Ph.D., since 2025, Sun Yat-sen University
Embodied AI, Vision-Language-Action Model, Policy Learning
M.S.: Shanghai Jiao Tong University
B.E.: Xidian University (Top 5%)

Bingqi Liu
Ph.D., since 2026, Sun Yat-sen University
Humanoid Robot Manipulation,Policy Learning
M.S.: Imperial College London
B.E.: Beihang University
Mphil/Master Student

Meng Cai
Master, since 2025, SYSU
Human Motion Generation, Humanoid Robot Simulation
B.E.: Sun Yat-sen University

Yuyu Sun
Master, since 2026, SYSU
Humanoid Robot Manipulation,Human-Humanoid Robot Interaction
B.E.: South China Normal Univ. (Top 1%)

Xin Wen
Master, since 2026, SYSU
Embodied AI, Policy Learning, Reinforcement learning
B.E.: Sun Yat-sen University
Research Assistants

Xiaocong Zeng
3D Object/3D Scene Generation, Digital Twin
M.S.: Sun Yat-sen University
B.E.: Sun Yat-sen University

Wenzhan Li
Embodied AI, World Modeling, Policy Learning
M.S.: Tsinghua University
B.E.: Xi'an Jiaotong University
Alumni (Ph.D./Mphil/Master Students)
Selected for Tencent 2025 Project Up (Qingyun Program)
Current Position: Senior Researcher, WeChat Vision, Tencent, Beijing, China.
Current Position: Senior Researcher, Zhejiang Provincial Seaport Investment, Hangzhou, China.
Current Position: Machine Learning Engineer, Xiaomi AI lab, Beijing, China.
Current Position: Computer Vision Engineer, Tecent, Shenzhen, China.
Current Position: Ph.D. student, Fudan University, Shanghai, China.
Alumni (Research Assistant)
Current Position: Ph.D. student, MMLab, The University of Hong Kong (HKU), Hong Kong, China.
Current Position: Ph.D. student, Harbin Institute of Technology (HIT-SZ), Shenzhen, China.
Current Position: Master student, University of California San Diego (UCSD), CA, U.S.
Current Position: Master student, Stanford University, CA, U.S.
Current Position: Ph.D. student, University of Georgia, U.S.
Current Position: Ph.D. student, The Hong Kong University of Science and Technology, Guangzhou (HKUST-GZ), China.
Current Position: Ph.D. student, Xi'an Jiaotong-Liverpool University (XJTLU), China.
Current Position: Ph.D. student, Hong Kong Baptist University (HKBU), Hong Kong, China.
Current Position: Ph.D. student, Sun Yat-sen University (SYSU), China.
Current Position: Ph.D. student, The Hong Kong University of Science and Technology, Guangzhou (HKUST-GZ), China.
Current Position: Ph.D. student, University of Illinois Urbana-Champaign (UIUC), U.S.
Current Position: Researcher, Shanghai Artificial Intelligence Laboratory, China.
TEACHING
Instructor, Sun Yat-sen University, Shenzhen.
Instructor, Sun Yat-sen University, Shenzhen.
Instructor, Sun Yat-sen University, Shenzhen.
Instructor, The Chinese University of Hong Kong, Shenzhen.
Instructor, The Chinese University of Hong Kong, Shenzhen.
Instructor, The Chinese University of Hong Kong, Shenzhen.
Instructor, The Chinese University of Hong Kong, Shenzhen.
Taught by Prof. Liang Lin , @Sun Yat-sen University.
Teaching Assistant
Taught by Prof. Weishi Zheng , @Sun Yat-sen University.
2+2 International Undergraduate Program, all in English.
Teaching Assistant, Sun Yat-sen University.
Taught by Prof. Liang Lin , @Sun Yat-sen University.
Teaching Assistant
Taught by Prof. Alan L. Yuille from UCLA, @Sun Yat-sen University.
Summer Intensive Course, all in English.
Teaching Assistant
CONTRACT ME
Address: Shenzhen Campus of Sun Yat-sen University, Shenzhen, China
E-mail: ruimao.zhang@ieee.org or zhangrm27@mail.sysu.edu.cn
Phone: (0755)